Recursive Query를 활용한 카테고리 페이지 구현
Introduction
이번 글에서는 데이터베이스의 재귀 쿼리와 React에서의 재귀 렌더링을 활용하여 카테고리 페이지를 구현한 과정을 기록한다. 카테고리 데이터는 계층적 구조를 가지기 때문에 단순한 쿼리나 렌더링 방식으로는 원하는 결과를 얻기 어렵다. 이 글은 이를 해결하기 위해 사용된 기술과 해결 과정에서 직면했던 문제들을 다룬다.
카테고리 페이지 만들기
페이지 기본 구조
카테고리 페이지는 크게 두 가지 주요 요소로 구성된다:
- 카테고리 리스트: 선택된 카테고리의 상위 계층과 하위 카테고리를 보여준다.
- 카테고리 리스트 아이템 (책 카드 리스트): 해당 카테고리에 속한 책들의 목록을 카드 형태로 표시한다.
이 두 요소는 계층적 데이터를 기반으로 하기 때문에 데이터 처리 방식과 렌더링 로직이 밀접하게 연결된다. 특히, 리스트에 나오는 카테고리와 하위 카테고리를 동적으로 관리하려면 데이터의 연관성을 유지한 상태에서 유연하게 처리해야 한다.
데이터 처리
카테고리 페이지를 구현하기 위해 가장 먼저 필요한 것은 계층적 데이터를 효과적으로 추출하고 구성하는 것이다. 이를 위해 재귀 쿼리를 사용한다. 재귀쿼리에 대한 기본적인 내용은 해당 링크에 설명이 되어있다.
상위 부모와 자식 카테고리 추출 (재귀 쿼리)
카테고리 데이터는 계층적 구조를 가지며, 각 카테고리는 부모와 자식 관계를 통해 연결된다. 예를 들어 categoryId = 4668인 카테고리 기준으로:
- 해당 카테고리와 그 상위 부모 카테고리를 추출해야한다.
- 추출된 상위 부모를 기준으로 각 카테고리의 자식 데이터를 추가로 가녀와야 한다.
이 과정을 단순 쿼리로 처리하면 비효율적이고, 상호 참조를 관리하기 어렵다. 이를 해결하기 위해 재귀 쿼리를 사용한다. 재귀 쿼리를 활용하면 계층적 관계를 반복적으로 탐색하여 상위 부모와 자식 데이터를 동시에 추출할 수 있다. 아래의 그림은 재귀 쿼리의 상세 동작을 설명한다.
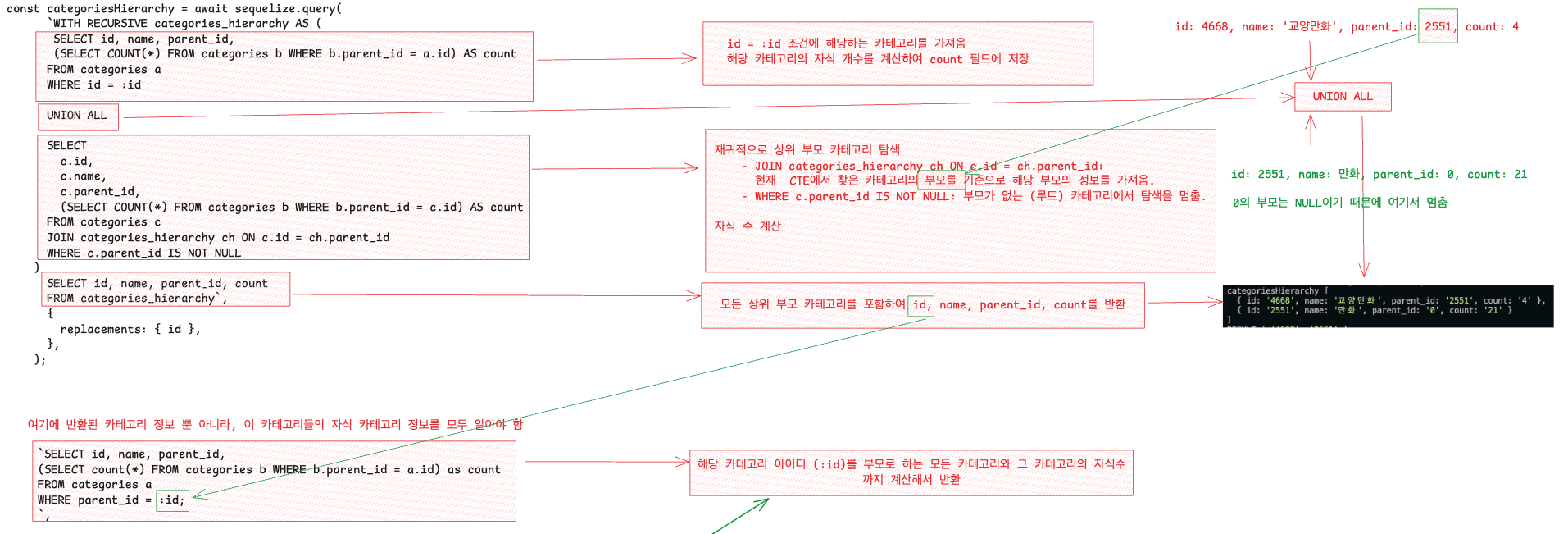
1. 첫 번째 단계: 기본 CTE 구성
WITH RECURSIVE categories_hierarchy AS (
SELECT id, name, parent_id,
(SELECT COUNT(*) FROM categories b WHERE b.parent_id = a.id) AS count
FROM categories a
WHERE id = :id
)
이 부분에서 id = :id 조건에 해당하는 카테고리를 가져오고, 해당 카테고리의 자식 개수를 계산하여 count 필드에 저장한다.
예를 들어 id = 4668 인 카테고리가 입력되면 해당 카테고리의 정보와 자식 개수 (4) 가 추출된다.
반환결과: id: 4668, name: ‘교양 만화’, parent_id: 2551, count: 4
2. 두 번째 단계: 재귀적으로 상위 부모 카테고리 탐색
UNION ALL
SELECT
c.id,
c.name,
c.parent_id,
(SELECT COUNT(*) FROM categories b WHERE b.parent_id = c.id) AS count
FROM categories c
JOIN categories_hierarchy ch ON c.id = ch.parent_id
WHERE c.parent_id IS NOT NULL
- categories_hierarchy 에서 현재 찾은 카테고리의 parent_id를 기준으로 상위 부모 카테고리를 탐색한다.
- 상위 부모 카테고리의 자식 개수를 계산하여 함께 반환한다.
- 부모가 없을 때 까지 (parent_id = NULL) 반복 된다.
예를 들어 id=4668의 부모 parent_id = 2551을 탐색한다.
반환결과: id: 2551, name: ‘만화’, parent_id: 0, count: 21
3. 최종 결과: 모든 상위 부모와 자식 데이터 반환
SELECT id, name, parent_id, count
FROM categories_hierarchy
- 재귀적으로 탐색된 모든 카테고리 데이터를 반환한다.
- 결과에는 입력된 카테고리 (id = :id)와 그 상위 부모 카테고리가 포함된다.

재귀 쿼리의 필요성
재귀 쿼리는 단순히 카테고리 데이터를 가져오는 것이 아니라, 상위 부모와 자식 간의 관계를 탐색하는 데 초점을 맞춘다. 이로 인해 상위-하위 관계를 하나의 쿼리로 효과적으로 처리할 수 있다. 만약 이러한 쿼리가 없었다면, 여러 단계의 데이터 요청이 필요했을 것이고, 이는 성능과 코드 복잡도 측면에서 큰 단점이 되었을 것이다.
Map을 사용한 자식 카테고리 데이터 추출 및 저장
상위 부모 카테고리를 추출한 후에는 각 부모 카테고리의 자식 데이터를 가져와야 한다. 이를 통해 완전한 계층 구조를 구성할 수 있다. 아래의 이미지가 그것을 구현한 코드인데, 재귀 쿼리로 가져온 계층적 데이터를 처리하고, 각 카테고리의 자식 데이터를 Map 객체에 저장하는 과정을 설명한다. 이 과정은 React 컴포넌트에서 데이터를 효율적으로 관리하고 렌더링하는데 중요한 역할을 한다.

1. 재귀 쿼리의 결과 처리
let result = [];
console.log('categoriesHierarchy', categoriesHierarchy[0]);
for (let category of categoriesHierarchy[0]) {
result.push(category.id);
}
categoriesHierarchy[0]: 재귀 쿼리의 결과로 반환된 배열이다. 상위 부모와 선택된 카테고리의 ID, 이름, 자식 개수 등의 정보를 포함한다.result.push(category.id): 쿼리 결과에서 각 카테고리의 ID만 추출하여result배열에 저장한다.
반환결과: result = [4668, 2551]
이 배열은 선택된 카테고리와 상위 부모 카테고리들의 ID를 포함한다.
2. Map 객체에 데이터 저장
let categories = new Map();
for (let id of result) {
categories.set(id, await this.getChildrenCategories(id));
}
- Map객체 사용 이유:
- 키-값 구조: Map은 키-값 구조로 데이터를 저장하므로, 각 카테고리의 ID를 키로 사용해 해당 카테고리의 자식 데이터를 저장할 수 있다.
- 효율적인 조회: Map의
get메서드는O(1)의 시간 복잡도를 가지므로, 특정 ID의 데이터를 빠르게 조회할 수 있다. - 순서 보장: Map은 데이터가 삽입된 순서를 유지하므로, 렌더링 시 계층 구조를 직관적으로 표현할 수 있다.
this.getChildrenCategories(id):- 해당 ID를 부모로 가지는 자식 카테고리 데이터를 비동기적으로 가져온다.
- 결과는 각 카테고리의 ID를 키로 하여 Map에 저장된다.
반환결과: CATEGORIES: Map(2) { 4668 => [children], 2551 => [children] }
Map 객체를 사용한 장점
- 키-값 구조의 명확성:
- 각 카테고리의 ID와 그 자식 데이터를 논리적으로 연결하여 관리할 수 있다.
- 예를 들어,
categories.get(4668)을 호출하면 해당 카테고리의 자식 데이터를 즉시 가져올 수 있다.
- 효율적인 데이터 접근
- 데이터 탐색 속도가 배열보다 빠르다. 특히, 특정 키를 기준으로 데이터를 자주 조회해야 하는 상황황에서 성능이 크게 향상된다.
- 순서 보장
- 데이터가 삽입된 순서를 유지하므로, 상위 부모에서 하위 자식으로 내려가는 계층 구조를 그대로 유지할 수 있다.
- React 컴포넌트에서 렌더링 시 계층 구조를 직관적으로 표현할 수 있다.
- 유연한 확장성:
- 카테고리가 추가되거나 삭제될 때, Map을 사용하면 특정 키만 업데이트하면 되므로 코드가 간결해진다.
최종 구조: Map(2) { 4668 => [children], // 선택된 카테고리의 자식들 2551 => [children] // 상위 부모 카테고리의 자식들 }
데이터 전달과 렌더링
구성된 데이터는 React 컴포넌트로 전달되어 리스트 형태로 렌더링된다. 카테고리 데이터는 재귀 렌더링을 통해 동적으로 확장 및 축소될 수 있다.
재귀 렌더링을 활요한 카테고리 리스트 구현
아래의 코드는 계층 구조의 카테고리 데이터를 재귀적으로 렌더링하는 과정을 보여준다. 특히, 자식 카테고리를 가진 카테고리가 확장되었을 때, 그 자식 카테고리도 동일한 방식으로 렌더링하도록 설계되었다. 이를 통해 카테고리의 중첩된 구조를 시각적으로 표현할 수 있다.
1. renderCategory 함수의 역할
const renderCategory = (category, paddingLeft = 0) => {
return (
<React.Fragment key={category.id}>
<CategoryListItem
category={category}
categoryId={categoryId}
expandedIds={expandedIds}
onExpandCategory={onExpandCategory}
handleOnClickCategory={handleOnClickCategory}
/>
{expandedIds.includes(category.id.toString()) &&
categories[category.id]?.map((subCategory) =>
renderCategory(subCategory, paddingLeft + 4)
)}
</React.Fragment>
);
};
CategoryListItem렌더링CategoryListItem컴포넌트는 개별 카테고리를 렌더링하는 역할을 한다.- 프롭스:
- category: 현재 렌더링할 카테고리 데이터를 나타낸다
- paddingLeft: 계층 구조의 깊이에 따라 좌측 여백을 동적으로 조정하기 위한 값이다.
- 프롭스:
- 자식 카테고리 렌더링
{expandedIds.includes(category.id.toString()) && categories[category.id]?.map((subCategory) => renderCategory(subCategory, paddingLeft + 4) )}- 조건부 렌더링:
- 현재 카테고리가 확장된 상태라면 (
expandedIds.includes(category.id.toString())), 자식 카테고리를 렌더링한다.
- 현재 카테고리가 확장된 상태라면 (
- 재귀 호출:
- 자식 카테고리를 렌더링하기 위해 동일한
renderCategory함수를 호출한다. - 이때
paddingLeft값을 증가시켜 자식 카테고리의 시각적 구분을 명확히 한다.
- 자식 카테고리를 렌더링하기 위해 동일한
- 조건부 렌더링:
- 재귀 렌더링의 특징
- 동적 계층 구조 표현:
- 부모-자식 관계를 기반으로 계층 구조를 동적으로 렌더링할 수 있다.
- 자식 카테고리의 수와 깊이에 관계없이 재귀적으로 확장 가능하다.
- 조건부 렌더링:
- 확장된 카테고리만 자식 카테고리를 렌더링하므로 불필요한 렌더링을 방지한다.
- 사용자가 상호작용할 때만 필요한 부분이 렌더링된다.
- 가독성과 재사용성:
- 재귀 구조를 통해 코드가 간결해지고, 계층 구조의 깊이에 관계없이 동일한 로직으로 렌더링할 수 있다.
- 동적 계층 구조 표현:
- 재귀 렌더링의 장점
- 데이터와 UI의 일관성 유지:
- 계층적 데이터를 그대로 UI에 반영할 수 있어, 데이터 모델과 렌더링 결과 간의 차이를 최소화한다.
- 확장성:
- 카테고리 데이터가 추가되거나 변경되어도 재귀 로직만으로 모든 계층을 처리할 수 있다.
- 조건부 렌더링과 성능 최적화:
expandedIds를 통해 필요한 데이터만 렌더링하므로 렌더링 성능이 개선된다.
- 데이터와 UI의 일관성 유지:
CategoryList 컴포넌트의 구현
CategoryList 컴포넌트는 프롭스로 받은 카테고리 데이터를 Material-UI의 ListItem을 사용해 렌더링한다. 이때 컴포넌트가 올바르게 렌더링되기 위해 중요한 데이터는 다음과 같다:
categoryId: 현재 선택된 카테고리 아이디ids: 현재 선택된 카테고리와 그 위의 상위 부모 카테고리 아이디를 저장해놓은 배열
추가적인 배열에 카테고리 아이디를 저장해놓은 이유:
카테고리 페이지가 새롭게 렌더링이 되더라도, 선택한 카테고리가 변하지 않았다면, 해당 카테고리의 부모 카테고리들은 확장된 상태로 유지가 되어야 한다. 하지만 카테고리 페이지가 새롭게 렌더링이 되면 그 하위 컴포넌트들인 CategoryList 와 CategoryListItem 컴포넌트들도 재렌더링이 되고 이전에 확장되어있던 카테고리의 정보가 사라지게 되는 문제가 발생하였다. 그래서 useMemo라는 React hook을 사용해 categories 데이터를 기준으로 한 번 계산된 카테고리 ID를 저장했다. 이렇게 되면 categories가 변경되지 않는 한 계산된 작업은 다시 계산하지 않고, 이는 성능 최적화가 필요할 때 특히 유용하며, 대규모 데이터를 처리할 경우 불필요한 연산을 방지한다.
초기 확장 상태 관리: useEffect
사이트가 리프레쉬 되더라도 확장된 카테고리 상태를 유지하기 위해 useEffect를 사용한다.
useEffect(() => {
if (expandedIds.length === 0) {
const newExpandedIds: string[] = [];
if (ids.length >= 3) {
for (let i = 1; i < ids.length - 1; i++) {
newExpandedIds.push(ids[i].trim());
}
}
dispatch(setExpandedCategoryIdsRequest(newExpandedIds));
}
}, [ids]);
ids의 길이에 따른 의미는 다음과 같다:
ids.length === 1: 선택된 카테고리의 최상위 부모가 루트 카테고리임을 의미한다.ids.length === 2: 선택된 카테고리와 바로 위의 부모 카테고리만 존재한다.ids.length >= 3: 선택된 카테고리의 상위 부모가 두 개 이상 존재하며, 최상위 부모와 중간 부모 모두가 열려있어야 한다.
Conclusion
카테고리 페이지 구현 과정은 단순한 리스트 렌더링이 아닌, 계층적 데이터 구조를 효율적으로 처리하고 렌더링하는데 초점이 맞춰져 있다. 이번 구현을 통해 다음과 같은 점들을 배우게 되었다:
- 재귀 쿼리를 사용해 계층 구조 데이터를 효율적으로 가져오는 방법.
- 재귀 렌더링을 활용하여 동적인 리스트를 구성하는 방법.
- 성능 최적화를 위해
useMemo와useEffect를 적절히 사용하는 방법.
재귀 쿼리와 재귀 렌더링은 카테고리 페이지 외에도 계층적인 조직도, 파일 디렉토리 구조 등 다양한 Use Case에서 활용이 가능하다. 이를 통해 데이터 구고의 가능성과 적용 범위를 더 넓게 이해하게 되었다.
댓글남기기