Recursive Query 1
Introduction
데이터베이스에 있는 데이터를 브라우저에 표현하는 방식은 여러가지가 있다. 표로 나타낼 수도 있고, 라디오 버튼으로 선택을 할수 있게끔 나타낼 수도 있다. 그리고 계층형 구조, 다른 말로 Tree 형식 으로도 나타낼 수 있다. 만일 보여주고자 하는 데이터가 부모-자식의 관계성을 띄고 있고, 이를 브라우저에 그대로 나타내고 싶을 때 가장 보편적으로 쓰이는 구조가 Tree 형식 이 아닐까 싶다.
Tree 형식은 굳이 브라우저가 아니라도 볼 수 있다. 지금 이 글을 쓰고 있는 VS CODE에서도 이 구조를 확인 할 수 있다.
그리고 이 구조를 자주 볼 수 있는 웹사이트를 하나만 꼽으라면 온라인 서점일 것이다. 온라인 서점의 책들은 카테고리 별로 정리되어있고 사용자는 카테고리 목록을 열어 원하는 카테고리를 선택해서 해당 카테고리의 책들을 조회할 수 있다. 이것은 어쩌면 온라인 서점의 가장 기본적인 기능이라고도 할 수 있겠다.
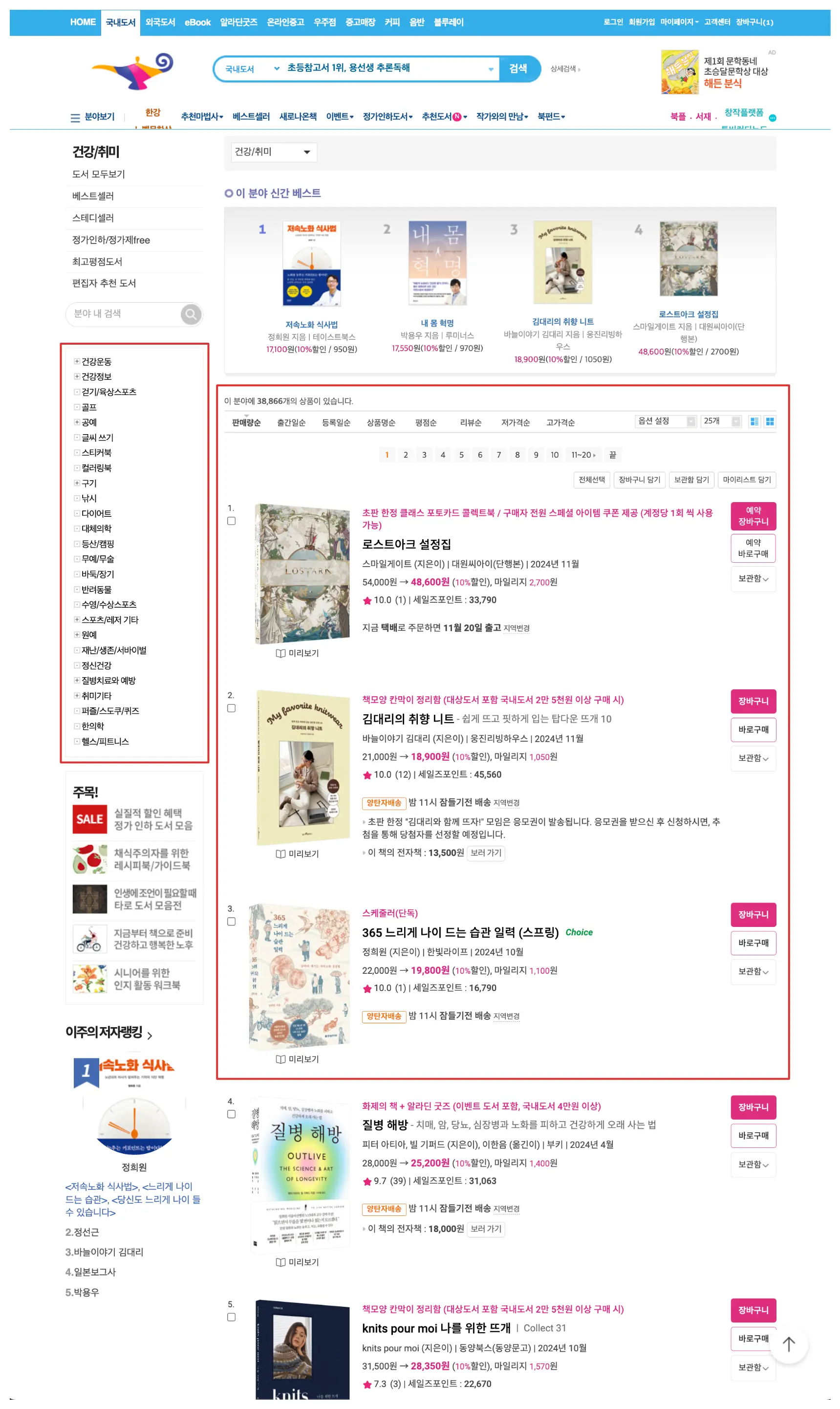
나도 현재 온라인 서점을 사이드 프로젝트로 만들고 있는데, 이제 이 “카테고리 조회” 기능을 만들어야 한다. 오늘은 이 기능을 구현하기 위한 가장 첫번째 단계인 데이터 처리 에 대해서 다뤄보려고 한다.
User Story
간단하게 이 기능의 User Story 에 대해서 설명하겠다. 웹사이트에 하나의 버튼이 있고, 그 버튼을 눌렀을 때 카테고리 목록이 그리드 형식을 가진 팝업 창이 뜬다. 간단하게 다음과 같다.
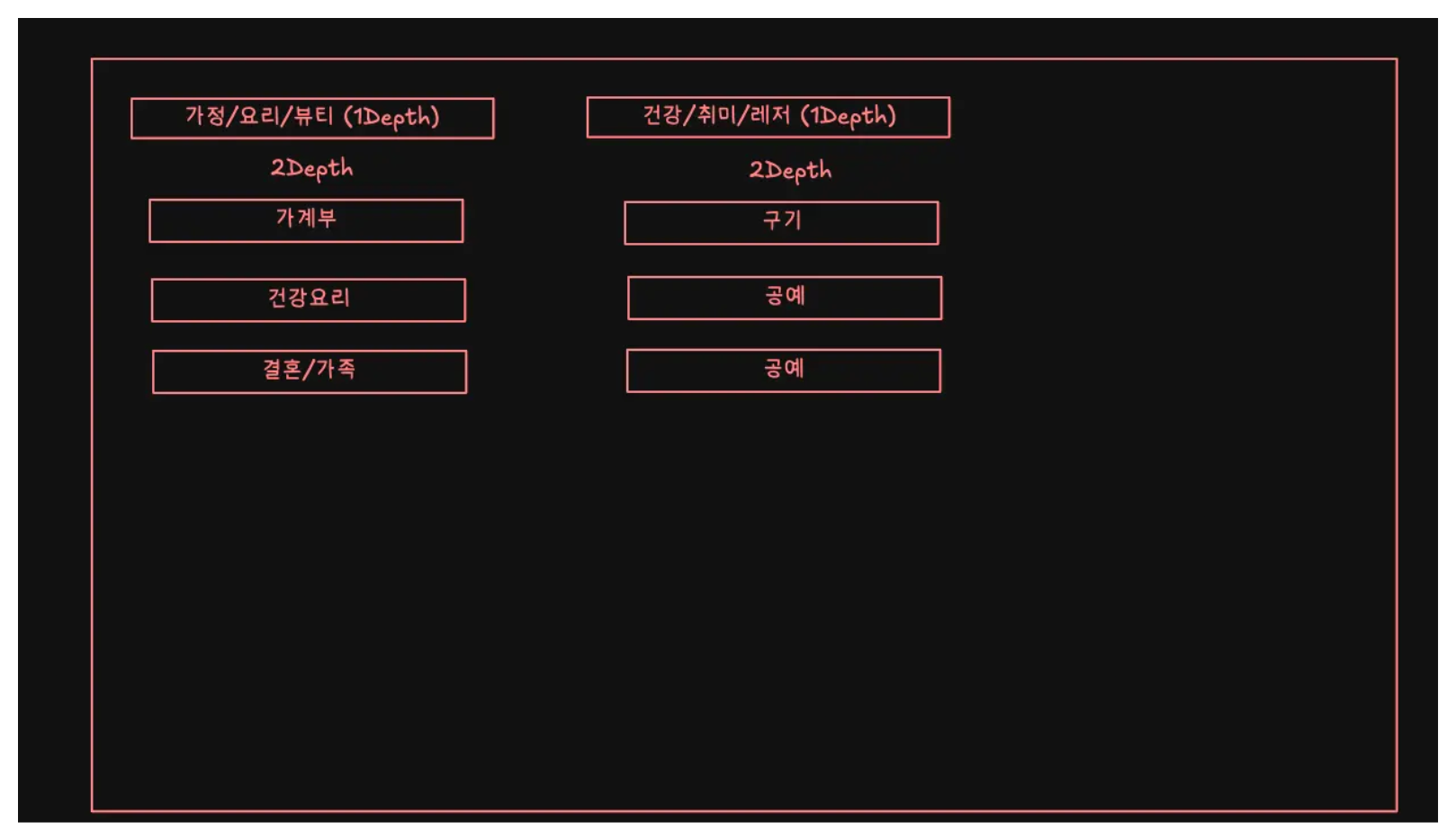
그림에서 보면 알 수 있듯이 카테고리 창에는 제일 최상위 카테고리는 나오지 않고, 두번째 레벨과 세번째 카테고리 (그림에서는 1 Depth, 2 Depth)의 카테고리 부터 나오게 된다. 이 팝업창을 완성하기 위해서 우리는 데이터 베이스에 있는 카테고리 테이블의 데이터 중 레벨 2와 레벨 3의 카테고리만 추출을 해내야 한다. 하지만 카테고리 테이블은 다음과 같이 생겼고, 레벨을 나타내는 column도 없다.
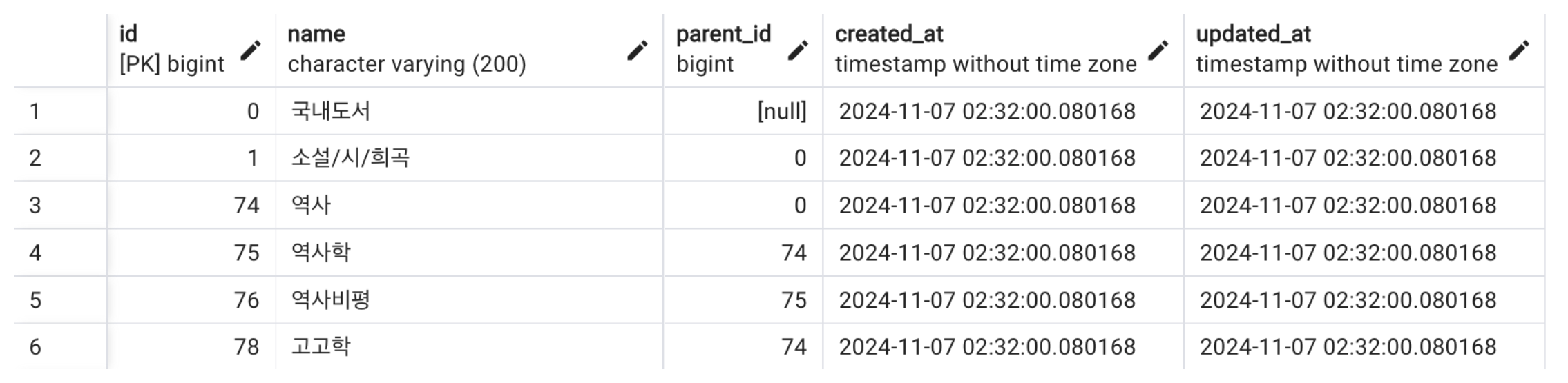
그렇다고 저 테이블에 있는 구조대로 데이터를 불러와서 프론트엔드에서 처리를 하기에는 프론트엔드에 부하가 많이 걸릴 것이다. 따라서 이런 경우에는 데이터 처리를 백엔드에서 해주고, 백엔드는 프론트엔드가 필요한 데이터만 보내주는게 성능적으로 좋다.
프론트엔드가 원하는 데이터를 보내주기 위해서 백엔드는 위 테이블과 같은 데이터 형식에서 깊이별로 데이터를 정렬하고 경로를 찾아내야 한다. 이때 사용하는 방법 중 하나는 재귀 쿼리, Recursive Query 이다.
Recursive Query
Recursive Query, 한글로 재귀 쿼리라고 하는 개념은 SQL에서 Common Table Expression (CTE)와 함께 사용하여 자기 참조(Self-referencing)를 통해 반복적으로 데이터를 조회하는 쿼리다. 계층적 데이터 (예: 트리 구조, 조직도, 카테고리 구조)를 탐색하거나 재귀적으로 데이터를 처리하는 데 사용된다. 이 때 계층 구조를 나타내는 hieracy 테이블을 임시로 만들어 데이터를 생성한다.
재귀 쿼리는 기본적으로 다음과 같은 두 가지로 구성된다.
- 기본 부분 (Anchor): 기본 부분에서 parent_id가
NULL인 최상위 카테고리 (루트)를 가져온다. - 재귀 부분 (Recursive Member): 재귀 부분에서 각 자식의 노드를 찾는다.
그리고 이 기본 부분과 재귀 부분의 쿼리를 합쳐서 하나의 hieracy 테이블이 임시로 생성된다. 이 테이블이 완성이 되면 최종 쿼리를 통해 원하는 데이터를 추출한다.
다음은 프로젝트에서 사용된 실제 코드이다.
const categoriesHierarchy = await sequelize.query(
`WITH RECURSIVE categories_hierarchy AS (
SELECT id, name, parent_id, 1 AS level,
name::VARCHAR as route
FROM categories
WHERE parent_id IS NULL --최상위 관리자 선택 (CEO)
UNION ALL
SELECT o.id, o.name, o.parent_id, oh.level + 1,
oh.route || '>' || o.name as route
FROM categories o
JOIN categories_hierarchy oh ON o.parent_id = oh.id
)
SELECT id, name, parent_id, level, route
FROM categories_hierarchy
WHERE level <= :level
ORDER BY level`,
{
replacements: { level },
},
);
이 코드를 위에 설명한 내용을 접목시켜 분석해보겠다.
WITH RECURSIVE categories_hieracy AS(): 이 부분에서 재귀 쿼리가 정의가 내려진다.categories_hieracy라는 테이블은 재귀 쿼리를 통해 만들어질 임시 테이블을 가리킨다. 그리고 이 테이블은AS뒤에 나오는 괄호로 정의가 내려진다.SELECT id, name, parent_id, 1 AS level, name::VARCHAR as route, ..., WHERE parent_id is NULL: 이 부분이 위에서 설명한 기본 부분 (Anchor) 이다. 그리고 이 부분에서 또 알 수 있는 건, categories_hieracy 라는 임시 테이블은id, name, parent_id말고도level과route(카테고리 경로) 라는 column이 추가가 되었다는 것이다. 최상위 카테고리는 level을 1로 갖고 route에는 카테고리 이름이 들어간다.-
SELECT o.id, o.name, o.parent_id, oh.level + 1, oh.route || '>' || o.name as route, ... JOIN categories_hieracy oh ON o.parent_id = oh.id:이 부분이 지귀 부분이다. 여기서 주목 해야할 점은 이 쿼리에서는 두 개의 테이블이 사용되었다는 점이다. 우선 원래의
categories테이블에서 기본 부분과 마찬가지로 id, name, parent_id가 불러와진다. 이 테이블을 편의상o라고 명명하였다. 그렇지만 모든 데이터를 다 불러와야 하는 것은 아니다. 우리는 이 부분에서 부모-자식 관계를 갖고 있는 데이터들을 추출해야 한다. 이 부모-자식 관계는 다음과 같이 정의 될 수 있다.자식.parent_id = 부모.id
여기서 부모 는 먼저 categories_hieracy 테이블에 저장된 데이터이다. 이 테이블에 데이터가 저장되는 Flow를 설명하자면 다음과 같다:
- 기본 부분에서 최상위 카테고리가 저장된다. 여기서
level은 1. - 재귀 부분에서
level 2카테고리들이 저장된다. 이 때 저장될 데이터는categories에서 오고, 비교는 1번에서 저장된 최상위 카테고리의 id와 비교가 된다. level 3의 카테고리들이 저장된다. 이 때 저장될 데이터는categories에서 오고, 비교는 2번에서 저장된level 2의 카테고리 id와 비교가 된다.
- 기본 부분에서 최상위 카테고리가 저장된다. 여기서
- 기본 부분의 쿼리와 재귀 부분의 쿼리는
UNION ALL으로 합쳐진다.UNION ALL은 두개의 쿼리를 중복을 신경쓰지 않고 합치는 명령어이다. 이 부분에 대해서는 나중에 따로 다뤄보도록 하겠다. - 이렇게 categories_hieracy라는 테이블에 데이터가 저장이 되고 나면, 최종적으로 쿼리를 할 수 있게 된다. 그리고 그것이 이 부분이다:
SELECT id, name, parent_id, level, route FROM categories_hierarchy WHERE level <= :level ORDER BY level여기서
WHERE구문은 선택적이다. 저런WHERE구문이 없을 경우에는 모든 레벨이 다 나오고, 저렇게 레벨 조건을 넣으면 특정 레벨까지의 카테고리가 계층 구조로 조회가 된다.
Conclusion
부모-자식 관계를 가진 데이터를 Row-Data 형태에서 계층 구조로 변환하는 방법 중 하나로 재귀 쿼리(Recursive Query)를 사용할 수 있다. 재귀 쿼리는 임시 계층 구조 테이블을 생성한 뒤, 자기 참조(Self-referencing)를 통해 반복적으로 데이터를 조회하여 계층 구조를 형성한다.
이 과정에서 level이라는 컬럼이 생성되며, 해당 컬럼에 각 노드의 깊이(Depth)가 저장된다. 이를 통해 계층 구조에서 특정 레벨의 데이터를 손쉽게 조회할 수 있으며, 프론트엔드에서 필요한 데이터를 백엔드에서 미리 가공하여 제공할 수 있다.
댓글남기기